Why I let an AI write code but never merge it
An AI agent writes a large share of the code I ship. It's fast, it's competent, and it's wrong often enough that I never let it merge its own work. A solo founder's case for keeping a human on the gate, and the controls that make it safe to hand a machine the keyboard.
I let an AI agent write a large share of the code I ship. It's fast, it's seldom as tired as I am, and most days it's genuinely better than me at the boring end of a task. It also has never once merged its own work, and as far as I'm concerned it never will. That isn't a grudge against the tool, it's the only way I can safely ship code.
The split I draw is simple. The agent can write, refactor, test, and propose. It can draft every FRD and tech spec. I review and approve each of those, assumption by assumption, before a line of code exists, and I gate every merge on CI passing (having first made sure CI isn't failing silently, which is its own story). Those last parts are mine, and I've come to think of them as a different kind of job entirely, not "the same work but slower," which is the trap everyone falls into with AI. When a machine can produce a plausible pull request in seconds, the obvious next thought is to let it produce the next one off the back of the first, and the one after that, until you're three changes deep in code nobody, you included, has actually read. Even though the code compiles, and the tests are green, you end up debugging something at midnight that you don't recognise, because you never controlled how it was added to your codebase. But hey, the agent will offer to fix that too.
The cause is pretty simple - an agent is very good at being locally correct and quietly globally wrong. It will write a function that does exactly what you asked, with a clean signature and a tidy test, that happens to undo an assumption three files away that neither of you was thinking about (assuming you knew the assumption was there at all, since most of us aren't reading the code that closely). It isn't lying and it isn't sloppy, it just doesn't carry the same model of the whole system in its head that I do, and it never says "I'm not sure about this part" whilst it's writing unless I've built something that forces it to. Confidence is a model's default setting, and that plays straight into our oldest bias: we believe things that are said confidently.
So the review isn't a formality I perform to feel responsible. It's the only place in the pipeline where someone holds the full picture and asks the questions the agent can't ask itself. Does this fit the shape of the thing we're building, or just the shape of the request? What did it quietly assume? What did it not touch that it should have? Those are judgement calls, and judgement is precisely the part that doesn't get faster when the coding gets faster.
If you're setting up your own AI development process
I get asked how to set this up, so here's the part you can actually copy. None of it is exotic, and that's the point, the controls are boring and well understood. What matters is that you wire them in before you let the agent loose, not after it's bitten you.
- Stop the agent pushing to main directly. Branch protection, no exceptions, including for you. Every change arrives as a pull request, so there's always a place for a human to stand between the code and production. If the agent can write to main, every other control is optional in practice.
- Make a human approve every merge. Not skim, approve. The review is where someone with the whole system in their head catches the locally-correct-globally-wrong change. This is the ring you never automate.
- Gate the merge on CI, and make CI fail loud. Tests, types, linting, security scans, all required to pass before merge is even possible. The harder part is making sure a check that should fail actually does, rather than quietly passing whilst it's stopped checking anything. A green tick you can't trust is worse than no tick.
- Move the judgement upstream. Have the agent write the plan or spec first, and approve that, assumption by assumption, before any code gets written. It's far cheaper to catch a wrong assumption in a paragraph than three files into an implementation that looks finished.
Think of those as rings around a centre, with the structural control (no direct push) on the outside and your own judgement at the core:
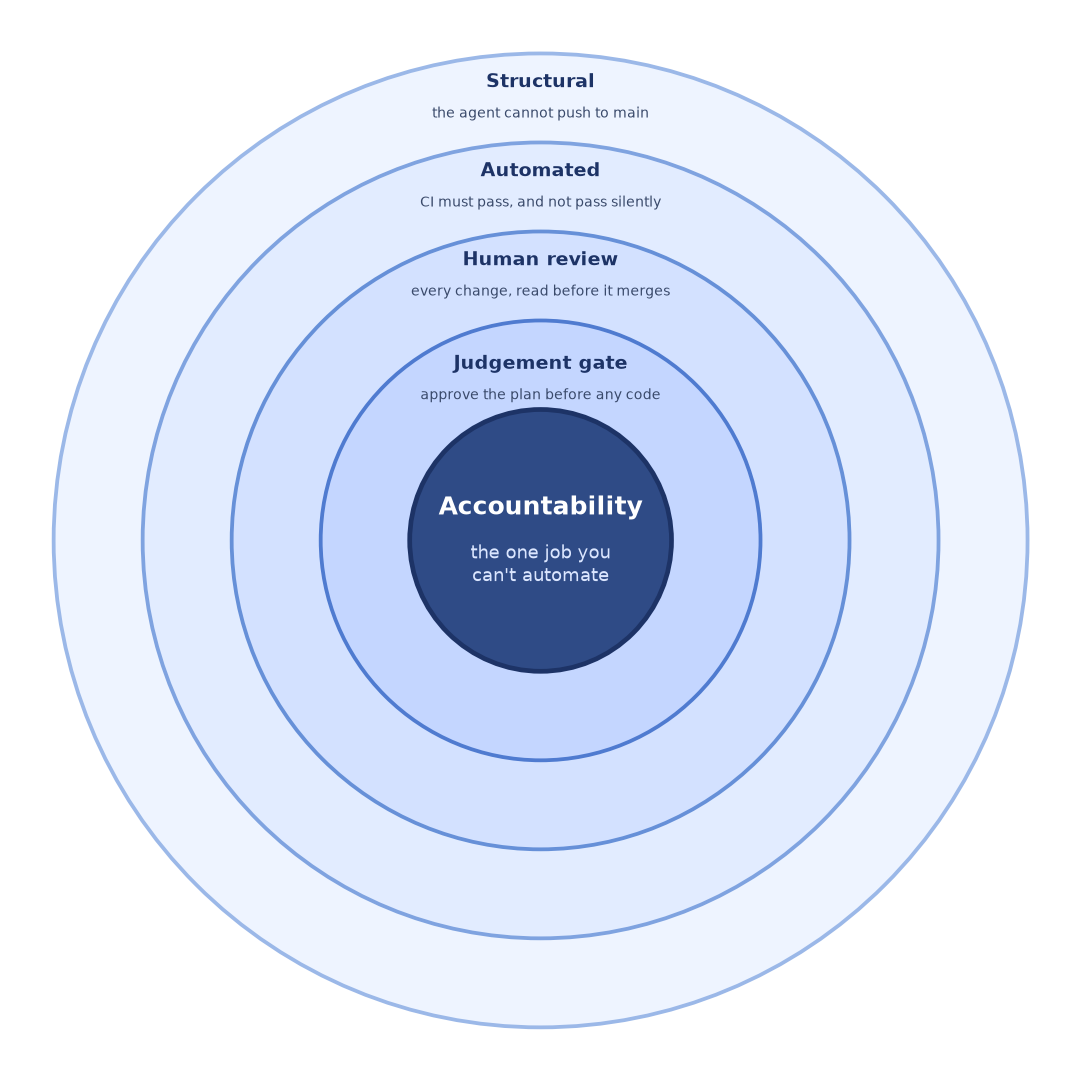
The outer rings exist to protect the inner one. Branch protection and CI aren't there to replace your judgement, they're there to make sure that by the time something reaches your eyes, you're spending that judgement on what actually needs it, instead of catching mechanical failures a machine should have caught first.
This is the whole principle, really, and it's worth saying plainly: automate the generation, never automate the gate where judgement happens. Let the machine write all it can. Just don't let it be the thing that decides its own work is good enough to ship.
People sometimes read this as me not trusting the tool, and that's backwards. I trust it plenty, for what it's for, and I'm clear-eyed about what this generation of it can and can't do. What I don't trust is the idea that being the last signature on an FRD or a change is a step you can hand to the thing producing the changes. Speed is wonderful, and I'll take all of it I can get on the coding. But somebody has to be accountable for what ships, and accountability isn't a thing you can automate. It's the one job that's still mine, and the day I let the agent merge its own work unread is the day I've stopped doing it.